Транскрибирование текста с изображений может оказаться настоящей проблемой. Когда текст представлен в виде изображения или другого невыбираемого формата, учеба и работа становятся трудными. Единственное решение — заставить глаза и пальцы работать и начать печатать — или нет?
Оптимальное распознавание символов, или OCR, – это процесс преобразования печатного или рукописного текста с носителя, например отсканированных документов или фотографий, в обычный текст.

Хотя возможны ошибки, зависящие от четкости текста, использование оптического распознавания символов для извлечения текста из изображений может сэкономить вам часы монотонной работы. Одним из вариантов использования OCR может быть случай, когда вы студент колледжа, которому нужна определенная страница из учебника. Если друг отправил вам фотографию страницы, вы можете использовать OCR, чтобы извлечь весь текст из изображения, чтобы его можно было легко прочитать и скопировать.
В этой статье давайте рассмотрим три лучших онлайн-инструмента OCR для извлечения текста из изображений, ни один из которых не требует загрузки каких-либо программное обеспечение оптического распознавания символов или плагинов.
Онлайн-распознавание текста
OnlineOCR – это один из самых простых и быстрых способов конвертировать изображение или PDF-файл в несколько различных текстовых форматов.
Без учетной записи OnlineOCR.net позволит вам конвертировать до 15 файлов в текст в час. Регистрация учетной записи дает вам доступ к таким функциям, как преобразование многостраничных PDF-документов и многое другое.
OnlineOCR.net поддерживает преобразование из форматов PDF, JPG, BMP, TIFF и GIF и вывод их в форматы DOCX, XLSX или TXT.
OnlineOCR.net может распознавать текст на английском, африкаанс, албанском, баскском, бразильском, болгарском, каталонском, китайском, хорватском, чешском, датском, голландском, эсперанто, эстонском, финском, французском, галисийском, немецком, греческом, венгерском, Исландский, индонезийский, итальянский, японский, корейский, латинский, латышский, литовский, македонский, малайский, молдавский, норвежский, польский, португальский, румынский, русский, сербский, словацкий, словенский, испанский, шведский, тагальский, турецкий и украинский.

Процесс преобразования состоит из трех простых шагов. Вы загружаете файл размером не более 15 МБ, выбираете язык и формат вывода и нажимаете кнопку Конвертировать .
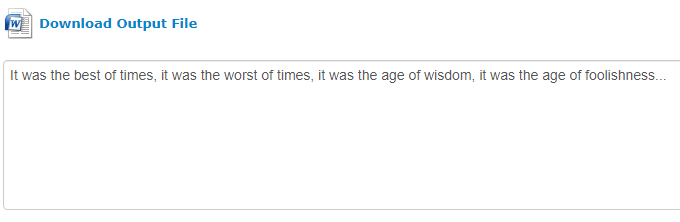
Независимо от выбранного вами выходного формата, предварительный просмотр преобразования в виде простого текста появится в поле под ссылкой для загрузки файла в выбранном формате. Это помогает пользователям не тратить зря загрузку на извлечение, которое может быть неточным..
Новый OCR
В настоящее время NewOCR предлагает только извлечение текста из файлов изображений, но поддерживает несколько других интересных функций, которых нет у многих онлайн-провайдеров OCR.
Чтобы начать использовать NewOCR, просто нажмите кнопку Выбрать файл , выберите изображение, из которого вы хотите извлечь текст, а затем нажмите синюю кнопку Просмотр . Откроется предварительный просмотр вашего изображения и появится несколько дополнительных опций.
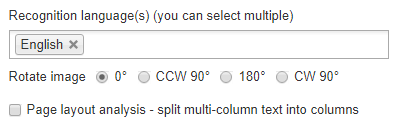
В отличие от большинства других онлайн-конвертеров изображений в текст, NewOCR позволяет вам установить несколько языков распознавания. Это может быть весьма полезно, если вы не уверены, на каком языке написан текст на изображении, но у вас есть хорошее предположение и вы хотите получить правильный перевод простого текста.
Если ваше изображение перекошено в одну сторону, вы также можете динамически повернуть его. Применив необходимые параметры, вы можете нажать синюю кнопку OCR , чтобы извлечь текст изображения.

Здесь вы можете скачать извлеченный текст в формате TXT, DOC или PDF или отправить его прямо в Google Translate или Google Docs для дальнейшего редактирования.
OCR.space
И последнее, но не менее важное: OCR.space определенно является одним из самых надежных вариантов, которые мы нашли, и он должен обеспечить практически любую операцию преобразования изображения в текст.
OCR.space — один из лучших инструментов OCR, поддерживающий формат файлов WEBP. Помимо этого, также поддерживаются PNG, JPG и PDF. Кроме того, вам не нужно загружать файл: вы можете удаленно создать ссылку на него, если он доступен где-то в Интернете.
Другие нишевые функции включают Автоматический поворот, сканирование чека, распознавание таблицы и автоматическое масштабирование. OCR.space — один из немногих онлайн-инструментов оптического распознавания символов, который поддерживает вывод файлов в формате PDF-файлы с возможностью поиска (с видимым или невидимым текстом), и вы даже можете выбирать между одним из двух разных Механизмы оптического распознавания символов. для наилучшего извлечения.
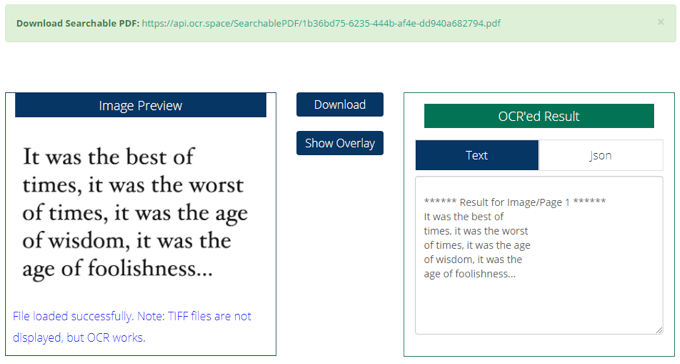
Все, что вам нужно сделать, это загрузить или связать файл, нажать кнопку Начать распознавание текста! , и предварительный просмотр ваших результатов будет динамически загружаться на той же странице. Если вы выбрали PDF-файл с возможностью поиска, кнопки Загрузить и Показать наложение также будут доступны.
Одной из наиболее интересных и уникальных особенностей OCR.space является возможность вывода извлеченных данных в формате JSON. Этот JSON будет содержать поля, включающие каждое слово в тексте и их координаты на самом изображении. Это очень ценная функция, если вы программист и пытаетесь программно реализовать извлечь текст из изображений..
С помощью трех вышеперечисленных веб-инструментов извлечение текста практически из любого четкого и разборчивого изображения будет проще простого. Даже если вы быстро печатаете с несколькими мониторами, вам не нужно самостоятельно расшифровывать текстовые изображения. Оптическое распознавание текста было создано не просто так, и эти веб-сайты помогут вам использовать его максимально эффективно!
Если у вас есть какие-либо другие советы по поводу лучших инструментов или услуг OCR, которыми вы хотели бы поделиться, или вам нужна помощь в использовании одного из вышеперечисленных, напишите нам сообщение в комментариях ниже.
p>.